At the 2018 International Symposium on Computer Architecture, John Hennessy and David Patterson delivered their Turing Lecture: "A New Golden Age for Computer Architecture".
In the 1980s, when Hennessy and Patterson did their Turing Award-winning research,
single-threaded CPU performance grew 52% a year. By 2018, with the end of Moore's Law and Dennard Scaling, the rate was 3%.
There was a need for domain-specific architectures (DSAs). Their worked example was Google's TPU v1, already in production: 29× the throughput of a CPU on neural-network inference, at 80× better energy efficiency. The closing prediction: "the next decade will see a Cambrian explosion of novel computer architectures."
This prediction came true. Today, we now have dozens of architectures in serious development. GPUs, TPUs, LPUs, NPUs, DPUs, ASICs, wafer-scale engines, reconfigurable dataflow, neuromorphic, photonic, analog. Particularly, these architectures focus on compute for AI.
This post aims to survey these varying approaches - their philosophy, architecture, scaling methods (scale-up and scale-out), and software stack (how you program the chip).
For now, I'm starting with NVIDIA GPUs, Google TPUs, and AMD GPUs.
The Problem
AI compute is dominated by matrix multiplication. A transformer is a sequence of matmuls: Q/K/V projection, attention, output projection, FFN - interleaved with element-wise ops: normalisation, activation, residual adds. Training a frontier model performs multiply-accumulate operations (matmuls are a sequence of multiply-accumulates).
The shape of those matmuls depends on the workload. Training pushes a batch of sequences forward through every layer, backpropagates the loss, and updates the weights, with thousands of tokens flowing through the same weight matrix at once. Prefill is the prompt-ingestion phase of inference: the full input sequence projected through the model in a single pass, before the first output token has been produced. Both training & prefill stack many tokens against the same weight matrix, so each layer's math is a large matrix-matrix multiply (GEMM), with high arithmetic intensity (compute-bound). Decode is autoregressive: the model emits one token at a time, each conditioned on every token before it, and token N+1 cannot begin until token N has been produced. Only one token gets projected per step, so every matmul becomes a matrix-vector product (GEMV). Producing one token requires a full pass over every weight in the model, plus a full read of the KV Cache for attention. Arithmetic intensity drops by orders of magnitude versus prefill.
Inference systems recover some of that intensity by batching tokens to promote those GEMVs back to GEMMs: continuous batching stacks many users' decode steps, speculative decoding stacks K drafted tokens per request and verifies them in one pass, and multi-token prediction folds the same trick inside the model itself. This achieves higher utilisation of the matmul units, and pushes up the Ops/B. For continuous batching, each user's request still reads its own KV Cache, so long-context decode shifts from weight-bandwidth-bound to KV-bandwidth-bound.
The architecture problem here is moving the numbers to where the matmuls happens fast enough. This is known as the memory wall: compute has scaled exponentially, memory bandwidth has not.
Each architecture proposes a different strategy for winning the data-movement game. Understanding a chip reduces to four questions: where does data live, how does it move to the compute units, what do the compute units look like, and how do chips talk to each other at scale.
NVIDIA GPU
The NVIDIA GPU is a massively parallel processor. The philosophy is that a programmable chip with thousands of threads, orchestrated by a host CPU and exposed through CUDA, is the right machine to run parallelisable workloads. Each generation adds acceleration primitives onto programmable Streaming Multiprocessors without changing the programming model. The same chip trains transformers, serves inference, renders graphics, and runs scientific simulation (accelerated computing).
Genealogy
Architecture
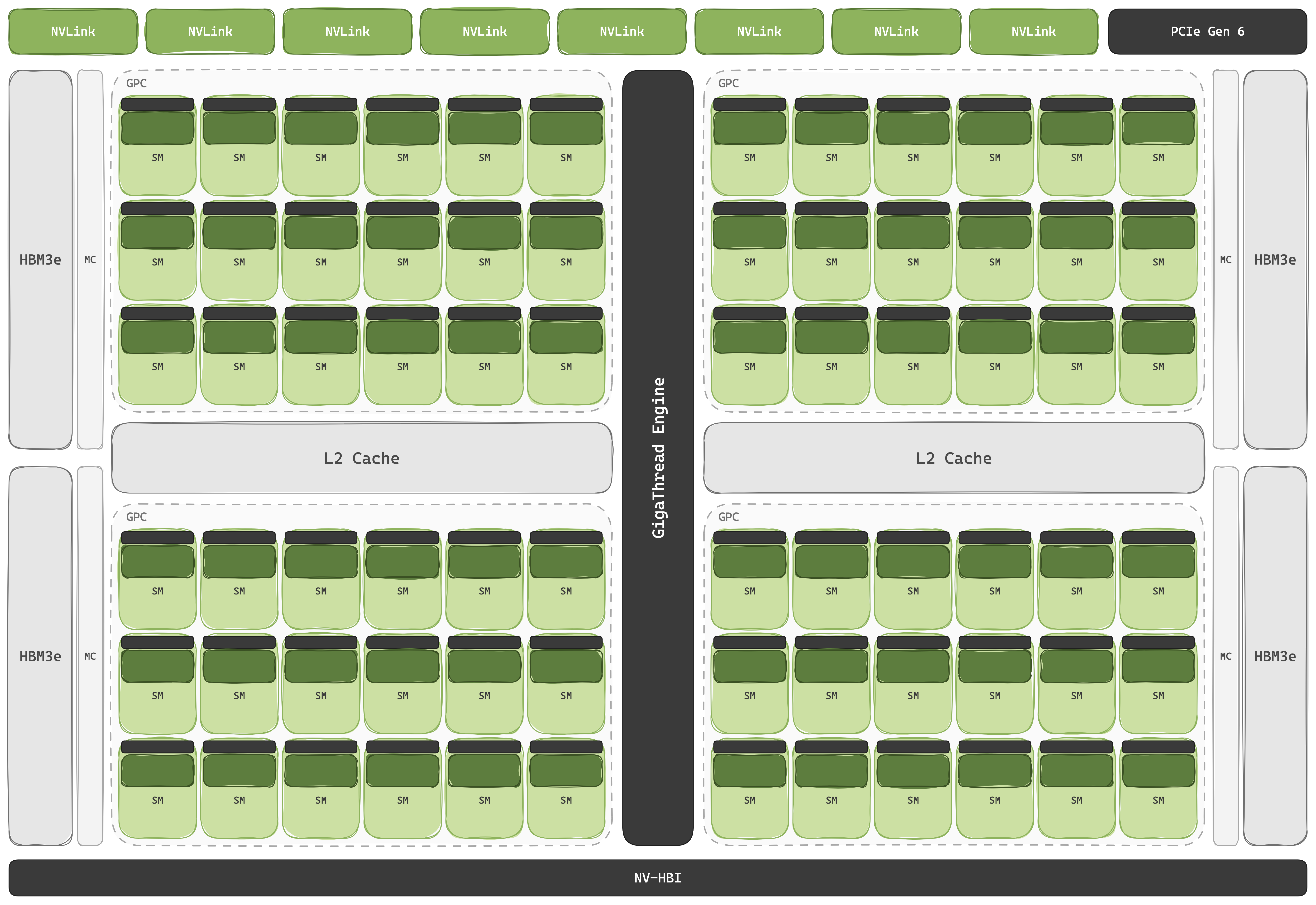
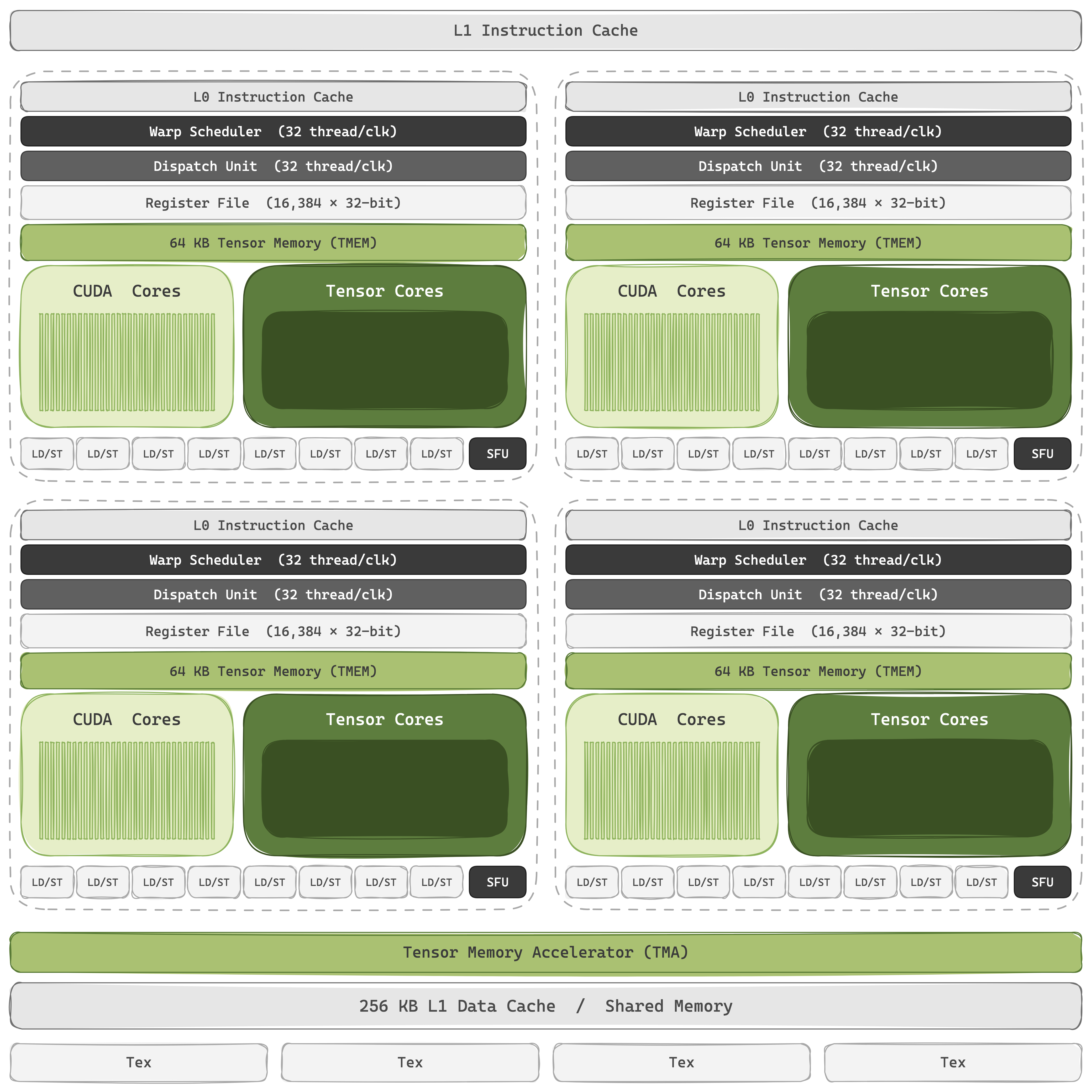
An NVIDIA GPU is a group of throughput-oriented cores, a deep memory hierarchy to keep them fed, + just enough scheduling silicon to keep thousands of threads in flight. The cores are Streaming Multiprocessors, replicated 100+ times per package: 80 on V100, 108 on A100, 132 on H100, 148 on B200, 160 on B300, 224 on Rubin. Inside every SM sits the same recipe: four SM Sub-Partitions, each with its own warp scheduler, dispatch unit, 16k×32-bit register file, scalar CUDA Core lanes, a Special Function Unit for transcendentals, and a private port into the SM's Tensor Cores. The four partitions share an L1/shared-memory block, and the TMA. Threads are grouped into warps of 32 that execute in SIMT lock-step; dozens of resident warps per partition let the scheduler hide memory/arithmetic stalls by switching between them.
Compute
CUDA Cores are the original compute throughput, and for AI they still own everything that isn't a matmul: activations, residual adds, normalization, address arithmetic. But, a transformer block is ~99% matmul FLOPs, so the overwhelming compute throughput comes from the Tensor Cores.
These cores execute fused matrix multiply-accumulate on small matrix tiles, The full matmul is broken into output tiles: to produce one output tile, a kernel walks the shared inner dimension , drawing from a row-strip of the left input matrix and from a column-strip of the right, and folds each partial product into a running accumulator. holds the partial sum so far, is the updated value carried into the next step. After the inner loop completes, is one finished tile of the full output matrix; the whole matmul is built from many of these tile MMAs.
Tile shapes are written M × N × K, is the output tile size, and is how much of the inner dimension the instruction contracts over in one fire; the rest of the matmul's axis is walked by the kernel's inner loop. The accumulator is sticky across that loop: each MMA's output becomes the next MMA's input , so the equation is really in place: successive instructions fold their partial products into the same storage until the K-axis is fully walked.
V100's first-gen unit (8 per SM) ran a warp-level 16×16×16 FP16 MMA. A100's 3rd-gen unit added TF32, BF16, FP64 matmul, and 2:4 structured sparsity. H100's 4th-gen unit added native FP8 and pulled the abstraction up from a warp to a warp group: 128 cooperating threads firing an asynchronous wgmma at 64×256×16 shape that runs in the background while the issuing warps load the next tile. B200's 5th-gen unit went further still: a two-SM MMA of 256×256×16 with operands split across a pair of SMs, native FP4, and a dedicated 256 KB Tensor Memory (TMEM) scratchpad per SM that holds accumulator tiles instead of bleeding into the register file. Rubin's 6th-gen unit extends FP4 throughput, adds native FP6, and pairs with a 3rd-gen Transformer Engine that does adaptive NVFP4 micro-block scaling in hardware, keeping the per-tile quantization metadata on the Tensor Core path, rather than through the CUDA Cores.
What stays constant across all six generations is that the matmul lives inside the thread/warp hierarchy, but the number of threads it takes to issue one has shrunk, and the issue itself has decoupled from execution. Volta's mma.sync is warp-collective and synchronous: all 32 threads in a warp execute it together, each lane holding register fragments of A, B, and the accumulator D, and the warp blocks until it completes. Hopper's wgmma.mma_async widens the issuer to a warp-group of 128 threads, moves B into a shared-memory descriptor (A becomes optional: either registers or a descriptor, kernel's choice), and returns immediately: the matmul runs in the background while the warp-group queues the next tile, with completion tracked via wgmma.commit_group / wgmma.wait_group.
Blackwell's tcgen05.mma completes the migration: A joins B in shared-memory descriptors (or A comes from TMEM directly), and the accumulator D lands in TMEM rather than the register file. With every operand off the lanes, there is no per-thread state for an issue to coordinate, so a single thread fires the instruction and returns immediately, with completion signalled by an mbarrier the consumer warp waits on. The rest of the warp, and the issuing thread itself, is free for other work in the meantime. A CTA-pair variant scales the same model across two SMs: one thread on each SM in a paired cluster issues coordinated MMAs that share operands across the pair, composing the 256×256×16 two-SM tile under the same async/mbarrier completion, just promoted to a cluster-level barrier so the pair stays in step.
The matmul has grown bigger and lighter on the issuing threads at the same time: an instruction that started as 32 lanes acting in lockstep is now closer to a single descriptor-driven command, dispatched from inside the warp model but no longer executed by it.
That decoupling is what makes transformer attention kernels efficient on a GPU. The warp can run softmax, apply a mask, or pre-load the next tile while the matmul is in flight; the overlap of matmul and the surrounding element-wise work is the structure of every modern attention kernel (FlashAttention-3, FA4), and it depends on the matrix instruction not blocking the warp.
Memory
The on-chip hierarchy is hardware-managed caches at every level, with software hints layered on top. Off-chip is HBM: 32 GB HBM2 on V100, 80 GB HBM3 on H100, 192 GB HBM3e on B200, 288 GB on B300, 288 GB HBM4 on Rubin. A chip-level L2 Cache sits between HBM and the SMs: 6 MB on V100, 40 MB on A100, 50 MB on H100, 60 MB on B200 (split into two 30 MB banks across the two-die package, with locality-aware residency controls so that hot tiles can be pinned to the near die). Inside each SM, 256 KB of unified L1/SMEM is partitioned at kernel launch between hardware-managed L1 and a programmer-controlled scratchpad. The register file is another ~256 KB per SM, sliced four ways across the partitions.
Blackwell adds a fifth tier: TMEM, 256 KB per SM dedicated to MMA accumulators and addressed only by the Tensor Core, pulling the operand-residency pressure out of the general register file.
Movement between tiers has been progressively decoupled from the warp. Pre-Ampere, loading a tile was synchronous: each thread issued its own global load, the warp blocked until every fragment landed in registers, and a second pass copied them to shared memory; every tile burned warp lanes on address arithmetic and on the wait. Ampere introduced cp.async: per-thread async copies HBM → SMEM that bypass registers entirely, with the warp committing groups of in-flight copies and waiting only when the consumer needs the data. Hopper replaced that with the TMA, a dedicated DMA engine: one thread submits a multi-dimensional tile descriptor (base address, leading dimension, swizzle), the engine handles all the address arithmetic and writes into shared memory, and completion is signalled by an mbarrier. The whole warp is freed from load issue and address math; the kernel just queues descriptors. TMA also supports cluster-level multicast: one HBM read fans out to every SM in a thread-block cluster, turning what used to be N separate loads into one. Blackwell extends TMA again: direct loads into TMEM, so accumulator tiles stream in without staging through SMEM. The trajectory is one less thing the warp has to do per tile, generation after generation.
Warp Specialisation
The Hopper-era programming idiom is warp specialisation: inside one block, some warps act as producers that issue back-to-back TMA loads; others act as consumers that fire wgmma on freshly-arrived tiles. Synchronisation between them is no longer the old SM-wide __syncthreads() barrier; it is mbarrier (memory barriers in shared memory) and asynchronous transaction barriers attached to TMA completions, allowing fine-grained producer/consumer handshakes at warp granularity rather than block granularity. The pattern that has become the reference for every modern attention kernel (FlashAttention-3, CUTLASS ping-pong GEMMs, the Blackwell FA4 kernel) is the same recipe: a TMA-driven producer pipeline feeds a wgmma consumer pipeline through shared memory and TMEM, with mbarrier handshakes and thread-block clusters (Hopper+) tying multiple SMs into one cooperative compute unit so that the two-SM MMA of Blackwell composes naturally on top.
Numerics
FP32 was the historical default; Volta brought FP16 with FP32 accumulate and the loss-scaling tricks that made it trainable; Ampere added TF32 (FP32 range, FP16 mantissa, drop-in for FP32 matmul), BF16, and 2:4 structured sparsity that doubles effective throughput on pruned weights. Hopper introduced native FP8 in both E4M3 and E5M2, paired with the Transformer Engine which auto-scales activations layer-by-layer to keep them inside FP8 dynamic range. Blackwell halved precision again with FP4 and shipped microscaling MX formats (block-level shared exponents that recover most of the accuracy lost at FP4), together with a 2nd-gen Transformer Engine that retargets the auto-scaling pipeline to FP4. Rubin's 3rd-gen Transformer Engine adds NVFP4 (NVIDIA's tightened FP4 variant) and native FP6 with more aggressive sparsity. The chip layout itself is now part of the numerics story: B100/B200/B300 are two reticle-limit dies stitched by a ~10 TB/s NV-HBI link and presented to software as one logical GPU, with 8 HBM stacks on the package; Rubin extends the chiplet recipe to dual-die at ~336 B transistors with 8 HBM4 stacks. Every generation buys roughly 2× per-watt throughput by cutting bits in half and restoring accuracy with a finer-grained scaling scheme, and increasingly, by bonding more silicon into the package.
Bets
- Bet 1: Programmability. The workload is a moving target (attention variants, novel model architectures), so keep every block programmable and let the developer write CUDA. Even the specialised units are exposed through that model rather than as fixed-function blocks.
- Bet 2: Hide Latency with Massive Multithreading. Latency is unpredictable and data-dependent, so hide it not with a static schedule but with massive thread overcommit, up to 64 resident warps per SM, with the hardware warp scheduler picking a ready warp every cycle.
- Bet 3: Warp-wrapped Matmul. The matrix unit is the overwhelming compute throughput, but it must live behind the same warp/thread abstraction that everything else uses, so wrap it in
mma.sync→wgmma→tcgen05.mma- rather than expose it as a fixed-function pipe. This enables a single kernel to fuse matmul, softmax, and element-wise ops in one pass. - Bet 4: Async Memory Hierarchy. Make the memory hierarchy explicit and programmer-managed rather than implicit and compiler-scheduled. Keep the L2 cache, but expose SMEM and TMEM as named scratchpads, and layer async machinery on top: TMA for bulk copies, TMEM for the matmul accumulator,
mbarrierfor the producer/consumer handshake. The hierarchy is software-pipelined inside a programmable kernel, not statically scheduled by a compiler against a known-latency scratchpad. - Bet 5: Amortised SIMT Tax. Every transistor spent on a warp scheduler, register-file, or coherent cache is a transistor not spent on a MAC; accept the tax, and pay it down two ways: a Tensor Core now big enough that the SIMT machinery is amortised across a much larger MAC count, and units like TMEM trading away some general-purpose flexibility for MAC density.
Scaling
There are two regimes for scaling: scale-up and scale-out.
AI infrastructure uses both: bandwidth-hungry collectives (tensor parallelism, MoE expert routing) stay inside the scale-up domain; data parallelism and pipeline parallelism cross the scale-out fabric.
Scale-up
The scale-up stack is NVLink plus NVSwitch. NVLink implements a cache-coherent fabric between GPUs, so a load or store on one GPU can target another GPU's HBM with the hardware handling address translation and coherence. But NVLink by itself is point-to-point: one link connects exactly two chips. NVSwitch is a dedicated crossbar chip that every GPU connects to, routing traffic so every GPU can simultaneously communicate with every other at full NVLink bandwidth, non-blocking and all-to-all.
Together they defined the HGX 8-GPU baseboard, pairing eight H100 SXM modules with x86 hosts (AMD EPYC or Intel Xeon) over PCIe Gen5. Hopper also shipped a Grace-paired form: the GH200 Grace Hopper Superchip bonded one Grace ARM CPU to one H100 over NVLink-C2C at 900 GB/s, eliminating the PCIe host-device hop. Modules scaled up into GH200 NVL2 pairs and rack-level GH200 NVL32. Blackwell makes the pairing the default. The GB200 module fuses one Grace with two B200s over NVLink-C2C, and NVL72 stitches 36 of them into a single liquid-cooled scale-up domain: 72 GPUs, 36 Grace CPUs, 13.5 TB of HBM and 17 TB of LPDDR5X as one flat, coherent address space. Rubin steps this in two. NVL144 ships in 2026 as a Rubin-generation refresh inside the same Oberon-class rack: 72 Rubin packages, badged as 144 GPUs under NVIDIA's new die-counting convention, with HBM4 and NVLink 6 doubling per-package bandwidth. The actual rack-scale jump is Rubin Ultra in 2027: NVL576 packs 144 four-die Rubin Ultra packages into the new Kyber chassis for 576 GPU dies in one coherent domain.

That density is held together by passive copper. NVL72's NVLink fabric runs over 5,184 cables blind-mated through a backplane (~2 miles of cabling per rack, no in-cable retimers, the SerDes living on the GPU and switch ASICs themselves), carrying ~130 TB/s of all-to-all bandwidth across the 72 GPUs. NVIDIA estimates the copper choice saves roughly 20 kW per rack against an optical equivalent that would have needed pluggable transceivers on every link. Copper is what makes rack as one GPU economically practical: at sub-2-metre runs it still wins on power, cost, and signal integrity per dollar; beyond that, the bits have to go on glass.
NVL144 stays inside Oberon and copper continues to work because the package count (72) is unchanged from NVL72; the cabling doesn't have to lengthen, just transmit faster on Gen 6 SerDes. Rubin Ultra's NVL576 holds the same copper line by reshaping the rack: the new Kyber form factor is roughly twice the height of Oberon and packs all 576 GPU dies into one enclosure, sized specifically so every NVLink path stays within passive-copper reach even at 144 four-die packages and tens of thousands of cables.
Scale-out
The scale-out stack comes from their acquisition of Mellanox. Unlike NVLink, scale-out fabrics are not coherent: nodes keep separate address spaces, and data crosses only via explicit RDMA initiated by software, typically wrapped in NCCL collectives like all-reduce or all-to-all. The reference cluster is the DGX SuperPOD: eight NVL72 racks stitched together over Quantum-X800 InfiniBand yield 576 Blackwell GPUs under a single scheduler, and training clusters scale further by tiling SuperPODs. Rubin SuperPODs in 2026 keep the same 8-rack pattern with NVL144 (yielding 1,152 GPUs per SuperPOD instead of 576). Rubin Ultra in 2027 scales the recipe up an order of magnitude: Kyber racks of 576 GPU dies each, stitched together over Quantum-X Photonics CPO, putting thousands of GPUs under one scheduler.
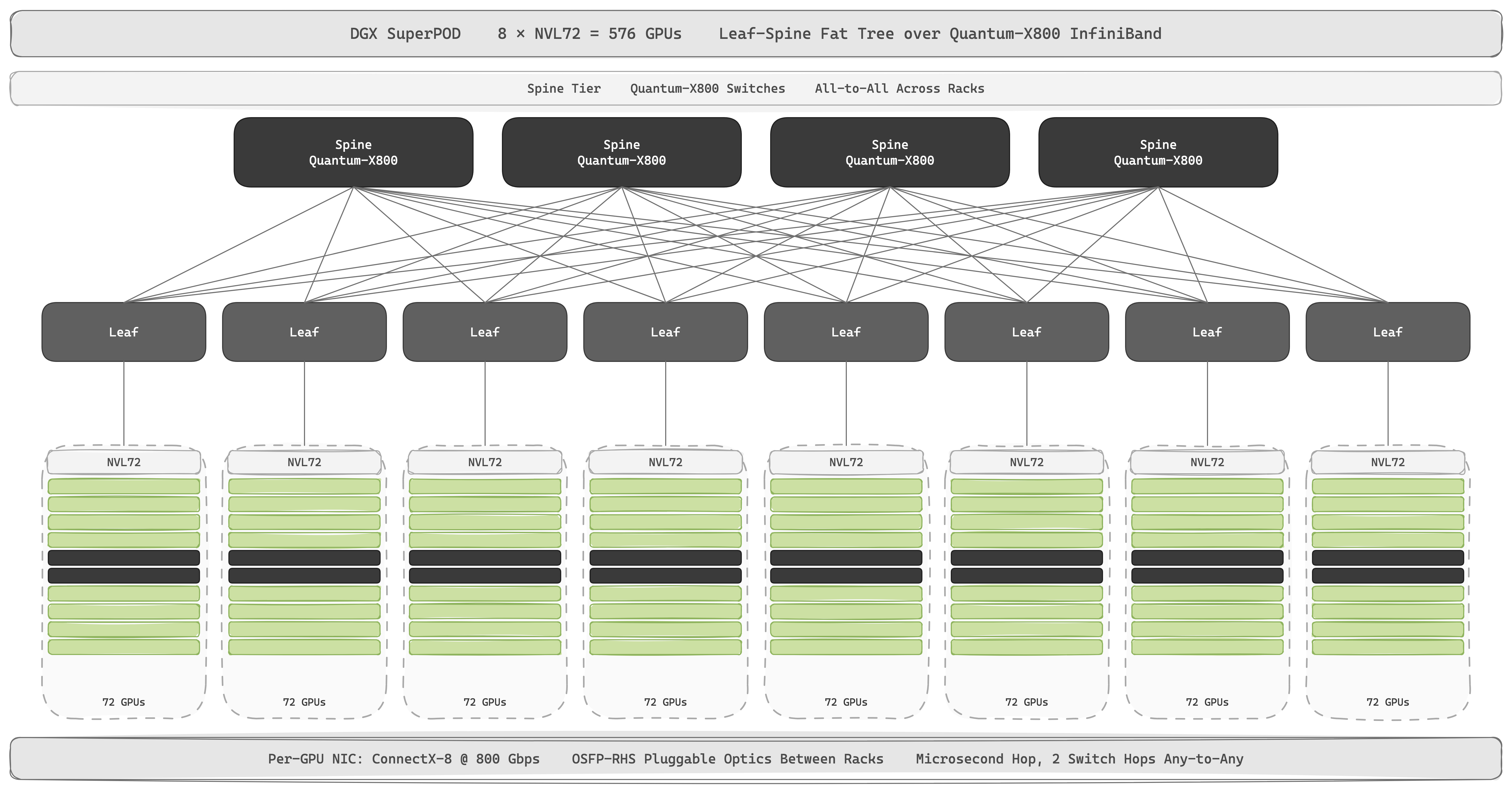
Every GPU has its own ConnectX NIC into that fabric. Blackwell nodes run ConnectX-8 at 800 Gbps per GPU, an order of magnitude less bandwidth than per-GPU NVLink, and latencies climb from nanoseconds to microseconds. Rubin moves to ConnectX-9 at 1.6 Tbps per GPU, doubling the per-GPU scale-out bandwidth as the per-rack scale-up domain grows from 72 to 576 GPUs. Alongside each NIC sits a BlueField DPU, adding ARM cores and accelerators to offload storage, networking, and security from the host CPU. For customers who prefer Ethernet to InfiniBand, Spectrum-X is a lossless-Ethernet alternative tuned for AI traffic.
The crossover from copper to glass happens at the rack boundary. Inside the NVL72 the spine is copper; once a link has to cross racks at 800 Gbps it is optical. Passive copper DAC tops out at roughly 1.5–2 metres at 200 G/lane, well short of cross-rack reach, so today's SuperPOD spine rides over OSFP-RHS pluggable transceivers, each module carrying its own laser, modulator, photodetector, and DSP. A SuperPOD spine fanning out to thousands of GPUs is, in optical terms, tens of thousands of pluggables drawing tens of kilowatts on transceiver lasers alone.
With Rubin, that optical layer collapses into the switch ASIC. Quantum-X Photonics (InfiniBand) and Spectrum-X Photonics (Ethernet) replace the pluggables with co-packaged optics: lasers, modulators, and photodetectors bonded onto the switch package via TSMC COUPE. NVIDIA claims ~4× fewer lasers and ~3.5× lower link power than the OSFP-pluggable equivalent. The chiplet logic that turned the GPU into a two-die package and stacked HBM next to it is now showing up at the network layer: vertical integration of compute, memory, and photonics on one substrate.
NVLink Fusion recently opened the scale-up fabric itself: third-party CPUs and XPUs can now join NVLink domains, letting hyperscalers build semi-custom racks around NVIDIA's interconnect without designing their own coherent fabric from scratch.
Software
CUDA is the natural programming model for a massively parallel processor. You write a kernel (one piece of code executed once per thread) and launch it across thousands of threads organised into blocks and warps; the programmer decides what they share, when they synchronise, and which piece of the problem each one handles. That is why the abstraction has barely changed in eighteen years, and why every CUDA kernel written since 2007 would still compile and run on Blackwell.
That continuity is both the moat and the constraint. Each new generation introduces new hardware (Tensor Cores, TMA, TMEM) onto the same kernel-and-warps model, exposed as intrinsics in PTX and SASS: mma.sync, wgmma.mma_async, and so on. NVIDIA cannot radically rethink the SM because too much code depends on it; in return, every investment in CUDA software compounds across generations.
On top of PTX sits a stack constructed over two decades. cuBLAS and cuDNN for math and DNN primitives; CUTLASS, encoding decades of GEMM expertise in templated C++; TensorRT-LLM for paged attention, in-flight batching, and speculative decoding; framework bindings through PyTorch, Triton, and JAX.
FlashAttention, one of the most important algorithmic rewrites in modern AI, tiles attention to avoid materialising the matrix. Its four generations (FA1 through FA4) have each been hand-optimised for the latest NVIDIA silicon (FA3 for Hopper's async pipelines, FA4 for Blackwell), with ports to other hardware trailing by months or years.
Most of this stack is written by people NVIDIA does not pay. The moat is not CUDA itself; it is two decades of third-party kernels, libraries, and tooling, and the millions of developers who have learned the API along the way.
NVIDIA also ships human expertise alongside the silicon. They embed dozens of their own engineers inside frontier labs and hyperscaler teams, writing kernels for each new model architecture and tuning them to each new silicon generation. Whatever a lab wants to train next month tends to run well on NVIDIA much faster than other platforms. Switching off NVIDIA is therefore not just rewriting the kernels and libraries. It is re-training the mental models of an entire engineering workforce, and losing the NVIDIA engineers who today sit inside the building.
Google TPU
The TPU is a matrix multiplication machine. The philosophy is, rather than a programmable chip that can run any massively-parallel workload, focus on a single primitive (dense matrix-multiplication on a large systolic array) and let the XLA compiler plan every cycle and every byte of memory ahead of time. No hardware scheduler, no cache, no threads/warps. Each generation grows the pod, with thousands of chips wired through the ICI interconnect into one coherent machine. A TPU has no ambition to render graphics or run scientific simulation; it exists to train and serve Google's workloads (search, translation, recommendation, Gemini) more efficiently per watt than any general-purpose alternative.
Genealogy
Architecture
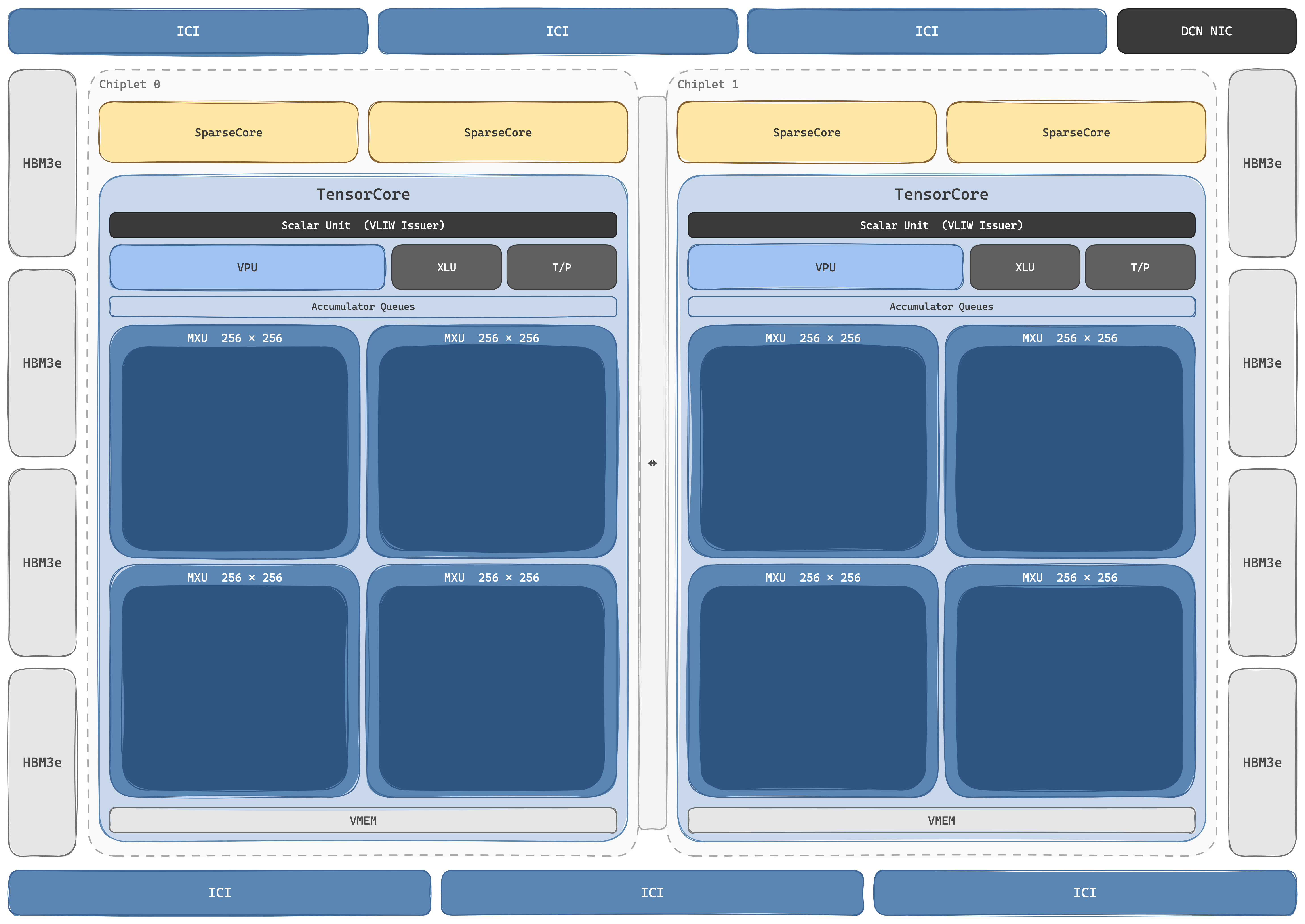
A TPU chip is a matmul engine wrapped in just enough silicon to keep it fed. The unit of compute is the TensorCore: flagship chips from v2 onward carry two per package; efficiency-tuned chips (v4i, v5e, v6e) carry one. Inside every TensorCore sits the same five-component recipe: one or more MXUs for matrix math, a VPU for element-wise math, a Scalar Unit that runs the show, an XLU for cross-lane reductions, and an attached Transpose/Permute Unit, plus accumulator queues feeding and draining the MXU. From v4 onward each chip also carries dedicated SparseCore dataflow engines outside the TensorCore (4 per chip on v4, v5p, and Ironwood; 2 per chip on Trillium), explicitly carved out to absorb the embedding-lookup workload the systolic array was the wrong shape for. Every block sits on a single VLIW issue plane driven by a Core Sequencer that fills all eight functional slots of a 322-bit bundle every cycle. There is no instruction cache miss, no warp scheduler, no out-of-order engine, no branch predictor: the compiler is the scheduler, and the silicon area saved is spent on more MACs.
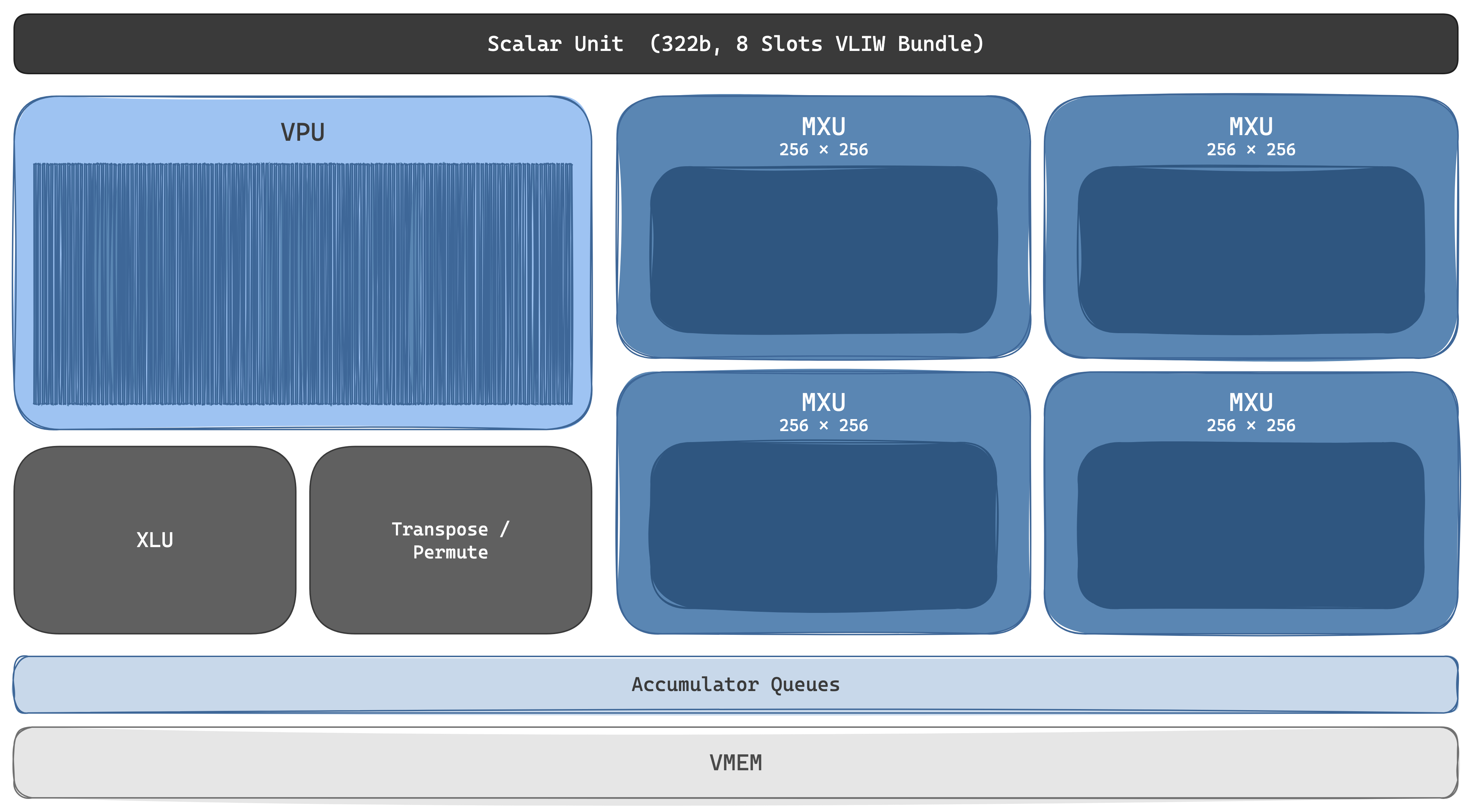
TensorCore
The MXU is the systolic array. v1 shipped one 256×256 INT8 inference array; v2 was the first training-capable TPU and introduced 128×128 cells doing BF16 multiply with FP32 accumulate (INT8 came back to the MXU at v4 onwards at equivalent throughput). Cell counts per TensorCore grew from there: 1 MXU on v2 → 2 on v3 → 4 on v4/v5e/v5p. Trillium went back to 256×256 (65,536 multiply-accumulate cells per array per cycle), and Ironwood, 8t, and 8i all kept the 256×256 shape.
To compute , matrix B's values are pre-loaded one weight per cell: weight-stationary dataflow, the choice that distinguishes TPUs from output-stationary arrays elsewhere. Activations enter from the left edge, propagate one column per cycle, multiply against the resident weight at every cell, and partial sums flow downward into accumulator queues at the bottom. Once data enters the array no memory access occurs: each weight is reused for every activation that passes through, each activation is reused 128 (or 256) times across the row. Data reuse is wired into the silicon, not arbitrated by a cache. The dominant cost in computing is not the multiplication itself (a few picojoules) but reading and writing memory at 100–1000× more energy per access; the systolic array deletes that cost by construction. The trade-off is underfill: a 128×128 matmul on a 256×256 array wastes 75% of the silicon, so XLA tiles, pads, and schedules dimensions to multiples of 128 (or 256 on v6e+) and the model code is written with those quanta in mind.
The VPU is the second-fiddle compute engine but is in many ways the more interesting microarchitectural object: every TPU is a 2D vector machine, not a 1D SIMD machine. The VPU's register file holds 2D VREGs. On v4/v5p the shape is (8, 128): 128 lanes wide, 8 sublanes deep, 32 (v4) or 64 (v5p) registers per core, with 4 independent floating-point ALUs per (lane, sublane). The lane axis matches the systolic array's input width, so the lane count presumably widened to 256 alongside the MXU on Trillium and Ironwood; Google has not published post-v5p VPU dimensions. The sublane axis lets the VPU stream tiles through the MXU at one matmul per X clocks (where X is the sublane dimension). Most of the speedup in modern TPU programs comes from VPU/MXU overlap: quantisation, layernorm, softmax, activation, and bias-add all run on the VPU in the same cycles the MXU is running the matmul behind them. Cross-lane reductions (the awkward case for any 2D vector ISA) are handled by the XLU: slow, expensive, and a known compiler hot spot. Layout transforms that misalign with the 2D shape are absorbed by the dedicated Transpose/Permute Unit, sparing a round-trip through memory.
The Scalar Unit is the smallest block and arguably the most consequential: a single-threaded, dual-issue integer ALU with 32 32-bit registers and 4 KiB of SMEM for control state, paired with an Imem holding the program. It is the only block that does instruction fetch; every cycle it pulls a 322-bit VLIW bundle, executes its own two scalar slots locally (address arithmetic, loop counters, branches, sync-register checks), and dispatches the remaining six slots to the rest of the chip: 2 vector ALU (VPU), 2 vector load/store (HBM↔VMEM DMA), 2 matrix (push/pop the MXU queue). Synchronisation between blocks is explicit: sync flags track when MXU and VPU pipelines are busy, and the compiler inserts barrier checks rather than the hardware tracking dependencies. The Scalar Unit is what makes the rest of the TensorCore look like fixed-function dataflow: every cycle, one place decides what eight things happen, and there is no dynamic reorder buffer to undo a bad decision.
Memory
The on-chip memory hierarchy is the same idea as the compute side: there are no caches, every level is software-managed. Off-chip is HBM (16 GB on v2/v5e, 32 GB on v3/v4/v6e, 95 GB on v5p, 192 GB on Ironwood, 216–288 GB on the v8 generation), and on-chip is a hand-stacked tier of explicitly-addressable scratchpads. Closest to compute is VMEM, the vector scratchpad feeding both the VPU and the MXU input queues, sized 32 MiB on v4, 128 MiB on v5e, and stretched to 384 MiB on the inference-tuned v8i precisely to hold an entire KV cache on chip. Above it sits CMEM, introduced with v4 at 128 MiB: a slower, larger SRAM staging area between HBM and VMEM that absorbs fused-op intermediates. The Scalar Unit has its own SMEM (~10 MiB for control state on v4) and a tiny scalar register file. Every tensor in the program is pinned to one tier at compile time; XLA's buffer-assignment pass schedules DMAs across tiers so that data arrives just before the cycle that consumes it. The hardware does no prefetching, no eviction, no coherence; when the compiler gets it right, the array never stalls; when it gets it wrong, there is no fallback path.
SparseCore
The block outside the TensorCore that breaks the systolic mould is SparseCore, introduced with v4. Recommender and ranking models live on embedding lookups (billions of indices into vast tables), and the access pattern is the inverse of dense matmul: irregular, indirect, all-to-all. A 256×256 systolic array is exactly the wrong shape. SparseCore is a dataflow processor with 16 compute tiles and dedicated SPMEM scratchpads, sitting alongside the TensorCore and absorbing scatter, gather, and segmented-reduce primitives plus the data-dependent all-to-all traffic that sharded embedding tables generate. This achieves 5–7× speedup on embedding-heavy models for ~5% of die area and power. v4 shipped 4 SparseCores per chip, v5p kept that count, Trillium dropped to 2, and Ironwood went back to 4 (2 per chiplet on its dual-die layout). The v8i (Zebrafish) inference chip removes SparseCore entirely and replaces it with a CAE (Collectives Acceleration Engine) on the I/O chiplet: different problem (collective reductions during autoregressive decode), same idea (carve a small accelerator off the main core to absorb a workload the systolic array is the wrong shape for).
Numerics
TPU v1 was INT8-only inference; v2 switched this for BF16 as the canonical training format: same dynamic range as FP32, half the memory, no loss-scaling tricks. v4 reintroduced native INT8 support. Ironwood then added native FP8 support (both E4M3 and E5M2) for ~2× the throughput of BF16 in the same area. v8 adds native FP4 plus block-scale multiplication inside the MXU itself, which deletes the VPU dequant overhead that Ironwood still paid. Stochastic rounding is hardware-supported on every modern TensorCore: rounding decisions made by the lower mantissa bits acting as a probability, which preserves the expected value of low-precision accumulations across long training runs and is one of the small details that lets BF16/FP8 close the accuracy gap to FP32.
At the chip boundary sit the ICI ports themselves (4 ports on the 2D-torus chips v2/v3/v5e/v6e, 6 on the 3D-torus flagships v4/v5p/v7/8t), and the DCN NIC for scale-out. From a chip-level perspective the ICI ports look like just another set of DMA engines the Core Sequencer can target inside a VLIW bundle: a remote-tensor send is the same instruction class as a VMEM-to-HBM transfer, and the compiler treats collectives as part of the same overall schedule it builds for compute and local memory.
Bets
- Bet 1: Systolic array. Matmul dominates the workload, so spend the silicon on a systolic array.
- Bet 2: Software scratchpads. Compute is cheap and memory is expensive, so reuse data in the wires of the array and replace caches with software-managed scratchpads.
- Bet 3: Compiler scheduling. The workload is statically predictable, so move scheduling into the compiler: VLIW issue, no speculation, no out-of-order, no dynamic scheduler.
- Bet 4: MAC-only silicon. Power matters more than peak, so delete every transistor that does not multiply-add: every cache tag, every branch predictor, every reorder buffer.
- Bet 5: Dedicated off-array engines. The dense matmul array is the wrong shape for some real workloads (embeddings, collectives), so carve out small dedicated engines (SparseCore, CAE) rather than warp the main core to fit them.
Scaling
The TPU's scale-up story is the inverse of NVIDIA's. Where NVLink + NVSwitch make every other GPU's HBM look like local memory (a hardware-managed coherent address space), Google's ICI is message-passing. There is no remote-load semantics, no cache coherence, no crossbar. Every multi-chip operation is an explicit collective compiled by XLA. The scale-up domain is tied together not by a switch fabric but by a torus (chips wired directly to their neighbours with edge wrap) and stitched at the rack boundary by optical circuit switches.
Scale-up
ICI links come straight out of the TPU die: high-speed serial lanes, direct-attach copper inside a 64-chip cube (a 4×4×4 arrangement that lives in one liquid-cooled rack), optical between cubes. Per-chip aggregate ICI bandwidth has scaled from ~250 GB/s on v2 to 1.2 TB/s bidirectional on Ironwood, and 2× that on v8t. Topology alternates by generation: 2D torus on the efficiency-tuned chips (v2, v3, v5e, v6e), 3D torus on the flagships (v4, v5p, v7, v8t).
The piece with no NVIDIA analogue is the Palomar OCS: a 3D-MEMS optical circuit switch that sits between cubes. Tiny mirrors physically rotate to map any input fibre to any output. A v4 superpod uses 48 Palomar switches to wire 64 cubes (4,096 chips) into one 3D torus; v5p and Ironwood scale the same scheme up. Reconfiguration is millisecond-class, not nanosecond, but that's fine, because OCS is circuit-switched: pick a topology at job start, run it for a week, then reconfigure for the next workload. Three problems collapse into one component: topology reconfiguration per workload (twisted tori give up to 70% better bisection), sub-pod slicing on demand, and fault tolerance (when a chip dies, the OCS optically swaps in a spare cube and the run continues without losing the ICI domain).
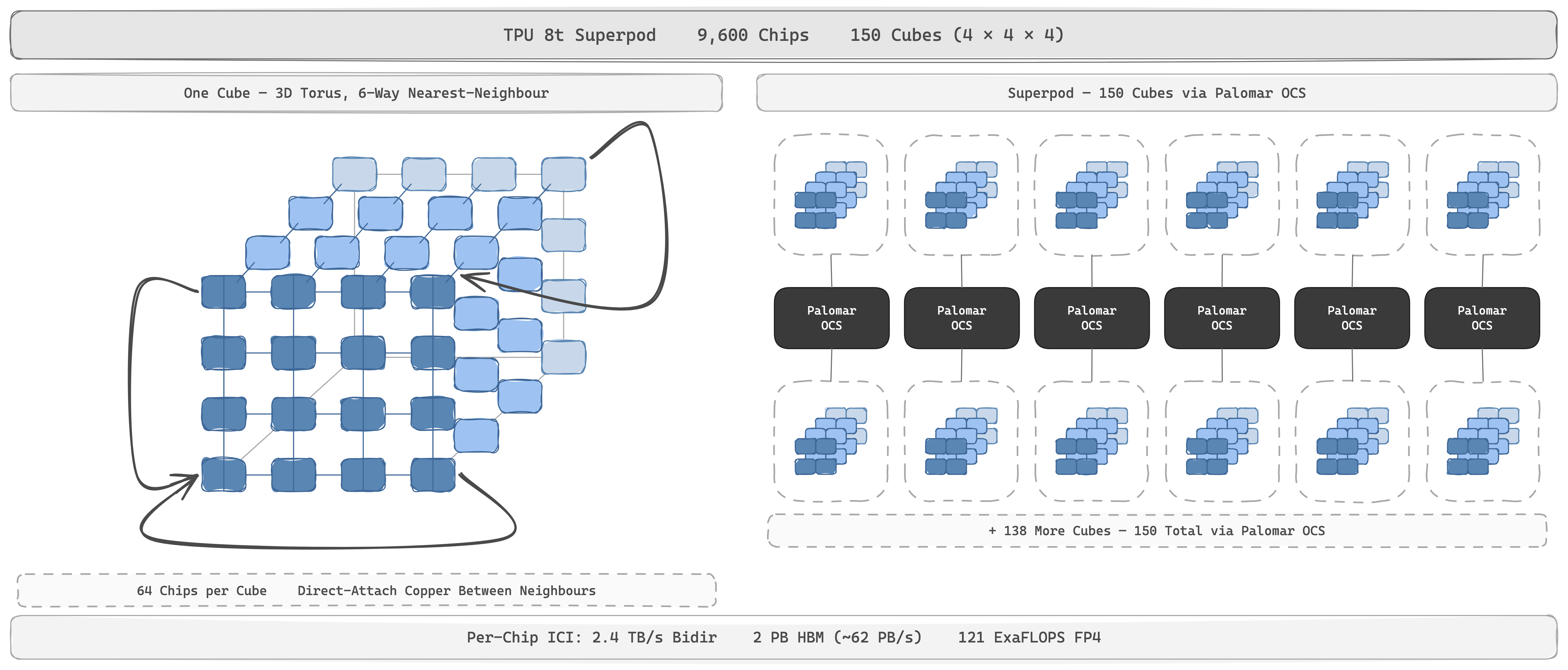
This makes the superpod the unit of scale-up: equivalent in role to NVIDIA's NVL72, two orders of magnitude bigger. v4 was 4,096 chips; v5p, 8,960; Ironwood (TPU v7) is 9,216 chips arranged as 144 cubes of 64, presenting 1.77 PB of HBM (~68 PB/s) and 42.5 ExaFLOPS FP8 as one coherent ICI domain.
TPU 8t (Sunfish) stretches this to 9,600 chips, 2 PB of HBM (~62 PB/s), and 121 ExaFLOPS FP4. TPU 8i (Zebrafish) has 1,024 chips, ~295 TB of HBM (8.8 PB/s), and ~10 ExaFLOPS FP4. 8i replaces torus with a new hierarchical high-radix topology called Boardfly (4-chip ring → 8-board group → up to 36 groups linked by OCS), cutting all-to-all latency in half. This is designed for MoE inference. A 3D torus excels when collectives are nearest-neighbour (ring all-reduce uses every link every cycle), but MoE expert routing is the opposite pattern, all-to-all: every chip ships unique fragments to every other, and round-trip latency is bounded by the longest-hop pair. A 1,024-chip 3D torus has a 16-hop diameter; Boardfly's ring → group → OCS hierarchy compresses that to 7.
Scale-out
Through TPU v7, scale-out ran over a single fabric: Jupiter, all-optical at the spine since 2022 via Apollo OCS, the same 3D-MEMS family as Palomar, scaled across the building. Google uses the same primitive (optical circuit switching) at every layer from rack to datacenter spine; that is the architectural signature nobody else has. Jupiter today carries 13 Pb/s of bisection per building.
With TPU 8t, scale-out split into two fabrics. East-west TPU-to-TPU traffic moved to Virgo, a dedicated accelerator fabric; Jupiter retained the north-south role: storage access, general compute, and inter-site scaling. Virgo is a flat, two-layer, non-blocking topology built on high-radix switches: every TPU is at most two switches from any other. One Virgo cluster links 134,000+ TPU 8ts at 47 Pb/s of bisection (4× the per-chip bandwidth and 40% lower unloaded latency than the prior DCN generation), with multi-planar fault isolation and sub-millisecond telemetry that lets the scheduler kill stragglers before they wreck a step. The architectural payoff is that each layer can now evolve independently: scale-up, east-west scale-out, and front-end can iterate on different cadences without rewiring the others.
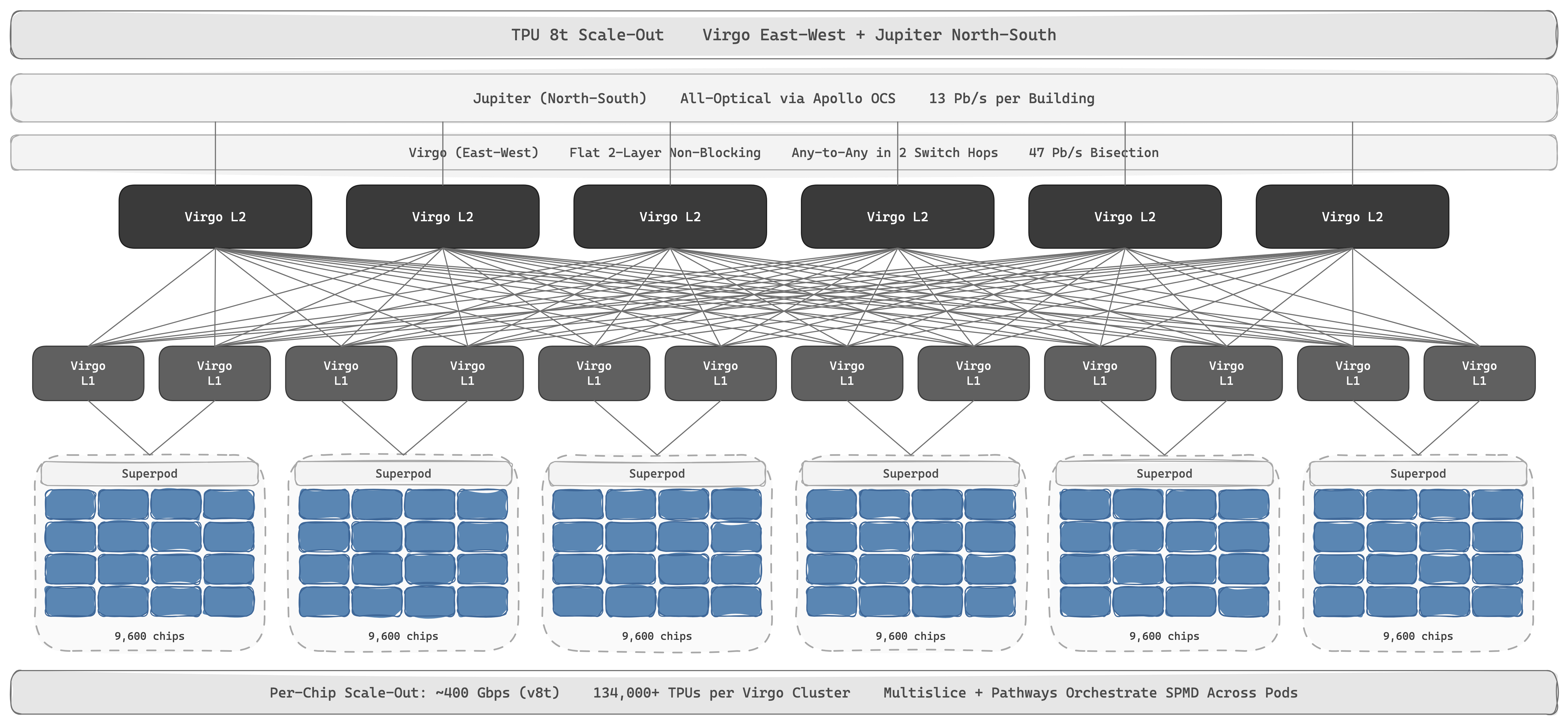
Per-chip scale-out bandwidth is on the order of 100 Gbps on Ironwood, and 4× that on v8t, but still two orders of magnitude less than per-chip ICI. This bandwidth gap dictates partitioning: tensor parallelism and MoE expert routing stay inside ICI; data parallelism and pipeline parallelism cross the scale-out fabric.
Google's Multislice framework, plumbed into XLA, lets a single SPMD program span multiple slices in different pods; the compiler emits hierarchical collectives (ring all-reduce inside each slice, higher-level reduce across). The structure is exactly the trick for hiding the ICI/DCN bandwidth gap: as much work as possible stays inside the slice over fast ICI, leaving only the cross-slice residual to pay the slow-fabric cost.
Above this sits Pathways. Where NCCL + Slurm + Megatron-style schedulers drive SPMD from many controllers, Pathways drives the entire job from one client and virtualises multiple "islands" (pods with their own ICI domains) connected over DCN. It does gang scheduling, elastic training (when a slice fails, OCS reshapes the topology and Pathways resumes from the last checkpoint on the new shape), and cross-region orchestration. Gemini Ultra was the first frontier model trained across multiple datacenters; Pathways stitches them into one synchronous SPMD job.
The philosophy: the compiler is the scheduler, the torus is the topology, and the optical switch is the universal reconfigurable substrate, at every layer from rack to datacenter.
Software
The TPU stack is compiler-driven where CUDA is kernel-driven. On a GPU, the developer writes the kernel and the framework strings kernels together; the compiler's job is mostly local. On a TPU, the developer writes a numerical program in JAX and XLA is responsible for everything below it: which operations fuse, where each tensor lives, how it is laid out across the 2D vector registers, when DMAs from HBM to VMEM issue, how the 322-bit VLIW bundles are scheduled, how the program shards across thousands of chips. There is no hardware fallback: no warp scheduler, no cache, no out-of-order engine to paper over a bad schedule. The compiler is the system. The trade-off is the central one of the architecture: XLA gets closer to the theoretical ceiling without hand-tuning, but closing the remaining gap is harder.
The compilation path is JAX → JAXpr → StableHLO → HLO → LLO → VLIW bundles. JAX traces a Python function into a typed functional IR (JAXpr) under jit, lowers it to StableHLO (the OpenXLA-standardised, versioned op-set of ~100 statically-shaped primitives that all front-ends now emit), which XLA ingests as HLO and runs through its pass pipeline: operation fusion (collapse pointwise + reduction + matmul into one kernel so intermediates never hit HBM), layout assignment (decide the 2D tiling of every tensor so it streams into the MXU without a transpose: substantially harder than on 1D SIMD machines because both the registers and the systolic inputs are 2D), buffer assignment (every tensor pinned to either VMEM, CMEM, or HBM with overlap windows pre-computed), SPMD partitioning, and finally a VLIW scheduler that fills all eight slots of every bundle. HLO lowers to LLO (Low-Level Optimizer), the TPU-specific IR, and LLO emits the final VLIW stream. A well-compiled program overlaps MXU systolic execution, VPU element-wise math, and HBM↔VMEM DMA in the same bundle every cycle.
Multi-chip execution is SPMD: one program, sharded data, hierarchical collectives, emitted by GSPMD (now being replaced by Shardy, an MLIR-native successor that lands as the default in early 2026). The user expresses sharding declaratively with Mesh + PartitionSpec annotations on a few key tensors; the compiler propagates shardings through the rest of the graph and inserts all-reduces, all-gathers, and reduce-scatters where the layout changes. When the compiler picks a wrong collective, shard_map drops the user into manual SPMD (per-device code with explicit local shapes and explicit collectives), composable inside jit so a single kernel can be hand-partitioned without giving up auto-partitioning everywhere else. This is the inverse of the PyTorch idiom: FSDP and DeepSpeed wrap the model in a runtime that issues collectives at module boundaries; GSPMD/Shardy partitions the whole graph as a compiler problem.
Pallas is the escape hatch: JAX's kernel-writing language, broadly the TPU equivalent of Triton on GPUs. Pallas kernels are written in JAX-flavoured Python, lowered through Mosaic (the MLIR-based TPU backend) to LLO, and embedded back into HLO as a custom op. It exists because XLA cannot always synthesise the optimum for novel attention variants, fused MoE dispatch, or anything that demands manual VMEM tiling and DMA scheduling: a FlashAttention-class optimisation, where the win is in the schedule and not the algebra. Pallas:Mosaic-GPU targets H100/Blackwell with the same front-end, so a kernel author can write once and lower to either substrate. The library tier above this is uniformly JAX-native: Flax NNX for modules, Optax for optimisers, Orbax for asynchronous distributed checkpointing, Grain for input pipelines, Tunix for post-training/RL, Qwix for quantisation. Google's reference training stacks (MaxText for LLMs including DeepSeek-V3-class MoE, and MaxDiffusion for Flux, Wan 2.1) sit at the top, in pure JAX; Pathways sits beneath, exposed to the user as pathwaysutils, so a single Python client can drive a job across thousands of chips and several pod-islands without giving up the JAX programming model.
The PyTorch path is real but second-class. torch_xla uses a LazyTensor mechanism: every PyTorch op records into an HLO graph that compiles on the next barrier, with the compiled artifact cached by graph-shape hash. PyTorch/XLA 2.x added GSPMD-style sharding annotations, torch.compile integration through an XLA backend, a JAX bridge, and (PyTorch/XLA 2.7) C++11-ABI builds with materially faster tracing. The gap to JAX is real (JAX's primitives map more cleanly to StableHLO, and complex parallelism strategies are better-covered), which is why vLLM TPU (powered by the tpu-inference plugin announced at Cloud Next 2025) lowers every model, JAX-defined or PyTorch-defined, through a unified JAX→XLA path. TorchTPU, announced April 2026, is Google's response: a native PyTorch experience with eager mode, torch.distributed, and torch.compile over XLA, on track to replace torch_xla.
Compared to CUDA, the TPU ecosystem is centralised, not sprawling. Almost everything below the framework (XLA, JAX, Flax, Optax, Pallas, MaxText, Pathways, Shardy, Mosaic) is open-sourced by Google itself, evolving in lockstep with the silicon. There are far fewer third-party kernels than CUDA's decades of accumulation; the moat is thinner where the workload looks weird, deeper where the workload looks like Gemini. The recent Ironwood (v7) "codesigned AI stack" language is the explicit framing: chip, ICI fabric, OCS, XLA, Pathways, Pallas, MaxText, vLLM, and Pathways co-released as one product, with v8t/v8i continuing the same model under a single tpu-inference lowering path. Triton and torch.compile narrow the gap on the NVIDIA side (kernel-driven and compiler-driven are converging), but the philosophical poles are still real: on TPU the compiler is the only interface that matters; on GPU the compiler is one of several.
AMD GPU
The AMD Instinct GPUs are built on a different bet from NVIDIA: where NVIDIA each generation expands what each SM can do, AMD has held the Compute Unit conservative since GCN (2012) and reinvested into the package: matched or beat the contemporary NVIDIA flagship on HBM capacity every generation since 2021; the first 3D-stacked datacenter GPU (CDNA 3); the first coherent CPU+GPU APU (MI300A); and an open ecosystem (ROCm, HIP, OCP MX, UALink).
Genealogy
Architecture
| AMD | NVIDIA |
|---|---|
| Compute Unit (CU) | Streaming Multiprocessor (SM) |
| SIMD | SM Sub-Partition |
| SIMD Lane | CUDA Core (FP32 ALU) |
| Wavefront (wave64) | Warp (warp32) |
| Matrix Core | Tensor Core |
| MFMA | mma.sync / wgmma / tcgen05.mma |
| VGPR / SGPR | Register File |
| LDS (Local Data Share) | SMEM (Shared Memory) |
| Infinity Fabric | NVLink |
Where NVIDIA's architectural ambition lives inside each SM (new tensor primitives, new async machinery, new operand stores each generation), AMD's lives between the CUs, in how many of them can be bonded into a single coherent package. The CU itself is conservative: four 16-lane SIMDs, one shared scalar unit, a 64 KB Local Data Share, an L1 vector cache, a per-SIMD VGPR file with a CU-shared SGPR pool, and (since CDNA 1) a Matrix Core running MFMA. The shape hasn't meaningfully changed since GCN in 2012; what scales is the count (120 CUs on MI100, 220 on MI250X, 304 on MI300X, 256 on MI355X) and the packaging that bonds them. A wavefront of 64 threads streams across the 16 SIMD lanes over 4 cycles, with many wavefronts resident per SIMD that the scheduler switches between to hide stalls. There's nothing exotic in here; what's interesting about CDNA is everything outside the CU.
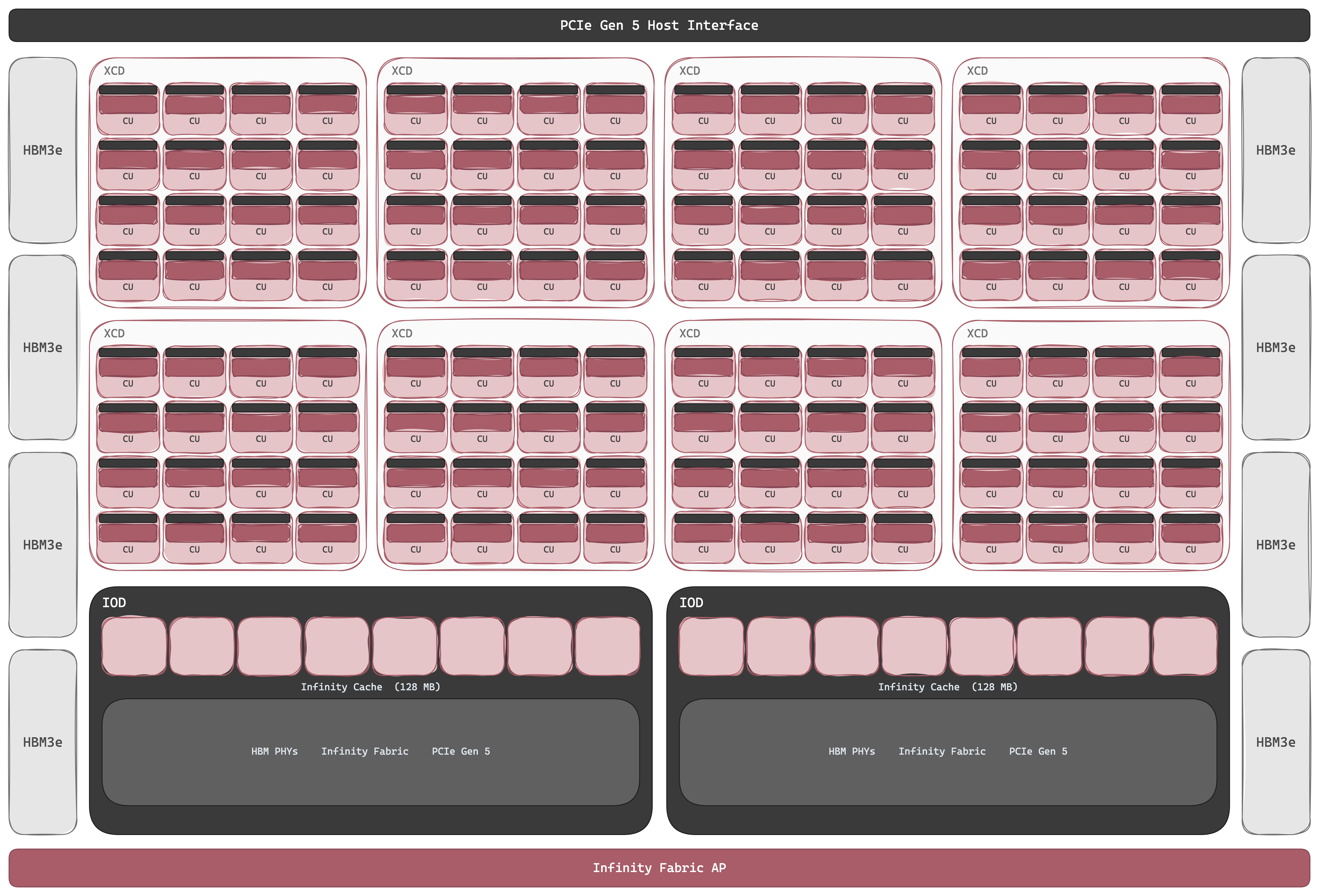
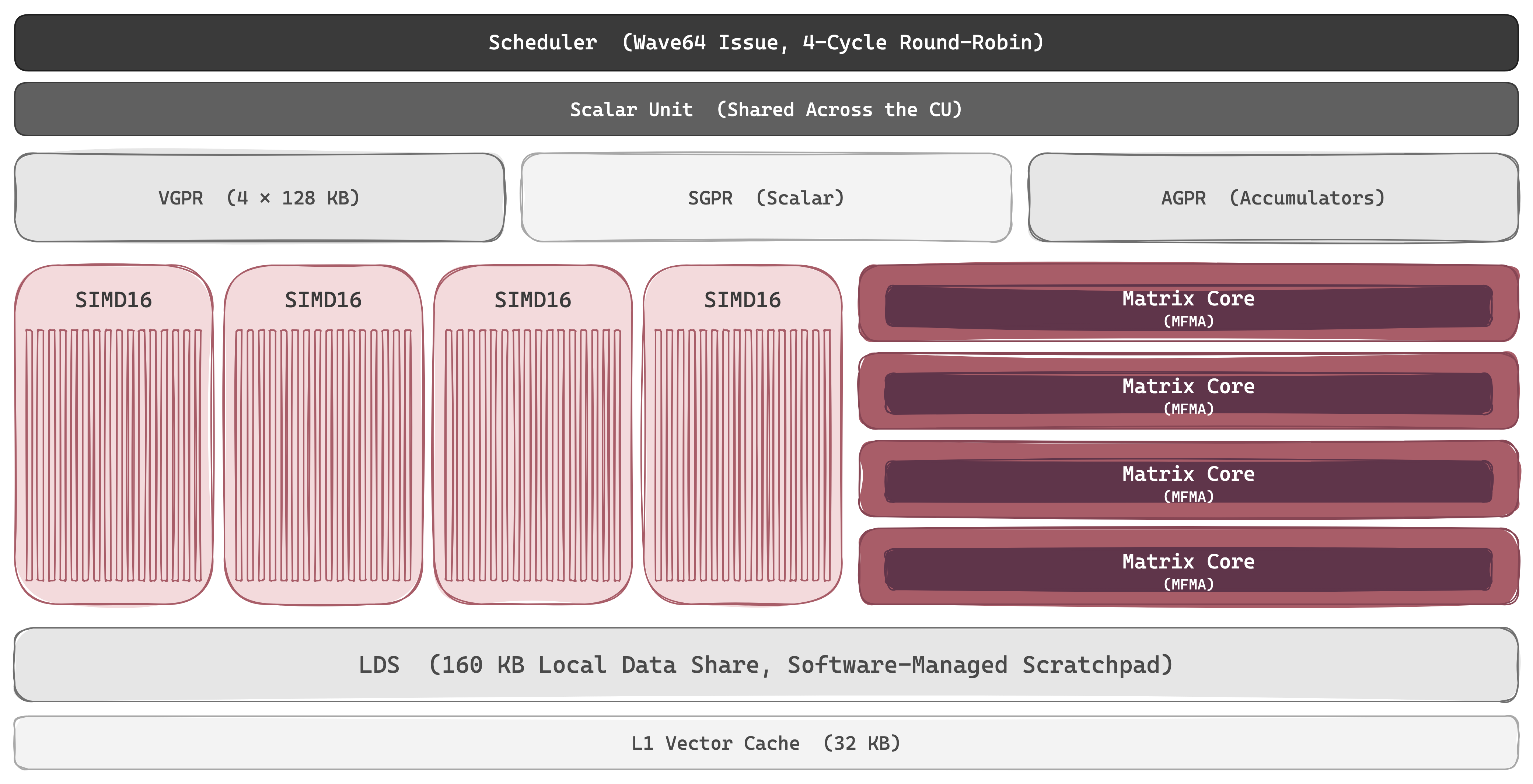
Compute
Inside the CU, the SIMDs and the Matrix Core run side by side. The four SIMDs handle everything element-wise: activations, normalization, residuals, address arithmetic. The Matrix Core handles the matmul. The split is the same as NVIDIA's CUDA Cores / Tensor Cores split, but the matrix abstraction has evolved on a very different curve.
NVIDIA's Tensor Core climbed the thread hierarchy: a 32-thread warp on Volta, a 128-thread warp-group on Hopper, a single thread plus an optional two-SM cluster on Blackwell. AMD's Matrix Core stayed put. Every generation of MFMA (from MI100 in 2020 through MI355X in 2025) is wavefront-scoped: one wave64 issues a single matrix op (V_MFMA_*), the four SIMDs cooperate to drive it, and operands come from the wavefront's register file: A and B from VGPRs, C and D usually from the dedicated AGPR file. The instruction got faster and the format set widened, but the issuer and the scope did not. The one feeder-side concession came with CDNA 4: a dedicated MFMA transpose-load from LDS that hands operands to the Matrix Core already in the layout it wants, small in spirit to NVIDIA's TMA, but the matrix op itself stayed wave-issued.
The throughput numbers tell the format story directly. CDNA 1 launched in 2020 with FP32 / FP16 / BF16 / INT8 at 256 / 1024 / 512 / 1024 FLOPs per CU per cycle, with native BF16 support alongside A100. CDNA 2 doubled the FP64 path to a full-rate matrix at 256 FLOPs/CU/cycle: uniquely AMD, the bet that put MI250X into Frontier. CDNA 3 reached parity with H100 on FP8 at 4,096 FLOPs (E4M3 + E5M2), added 2:4 structured sparsity, and added a TF32-equivalent path that runs FP32 matmul at the FP64-matrix rate by truncating mantissas. CDNA 4 doubled again to FP4 at 16,384 FLOPs and FP6 with OCP MX block-scaling, and added mixable A/B precision in one MFMA: FP8 × FP4, for example. The same generation halved per-CU FP64 throughput, the first AMD chip to trade HPC density for AI density rather than ship both.
The wavefront-scope decision shows up in two costs.
Divergence. A half-empty wave64 wastes 32 lanes where a half-empty warp32 wastes 16. For workloads with mostly-uniform control flow this is a small price; for irregular workloads it hurts.
Overlap. NVIDIA's asynchronous, descriptor-driven matmul decouples issue from execution: the issuing thread fires the instruction and moves on; the Tensor Core runs in the background; the warp can run softmax, apply a mask, or pre-load the next tile while the previous matmul is still in flight. AMD's wavefront-collective MFMA gives the wave no equivalent: the same wave that issued the matmul can't simultaneously do meaningful vector work while it's pending. Overlap is possible across separate wavefronts, but has to be staged in software with explicit wavefront barriers, which is more fragile and consumes more wave slots and registers.
How much this matters depends on the workload. Pure dense GEMM (DGEMM, the inner loop of large-batch training) has nothing useful to do during the matmul; both engines saturate; async buys little. These are exactly the workloads where AMD has historically led at exascale HPC (Frontier on MI250X, El Capitan on MI300A). Transformer attention (FlashAttention-3, FA4) interleaves matmul with softmax, masking, and KV-cache reads, and the async overlap is the whole structure of those kernels. AMD has to recreate the pipeline by hand, which lags NVIDIA's hardware-level support. MoE dispatch, paged attention, speculative decode sit in the same camp: address-irregular work that wants to run alongside the matmul.
NVIDIA's matrix-instruction abstraction has moved further across generations (warp → warp-group → single-thread async + cluster), and AMD hasn't followed.
Memory
AMD's memory hierarchy has fewer general-purpose tiers than NVIDIA's, with one giant cache that NVIDIA does not have at all. From the CU outward: a 64 KB LDS scratchpad (software-managed, 32-bank, AMD's analog of NVIDIA's SMEM), a vector L1 (16 KB on early CDNA, 32 KB from MI300X onward), a per-XCD L2 of a few MB. The L2 isn't coherent across XCDs, though; coherence happens one tier above L2.
That tier is the Infinity Cache: 256 MB on MI300X, distributed across the four IODs, 16-way set-associative, ~12 TB/s measured, more than twice MI300X's 5.3 TB/s of HBM3. It originated on RDNA gaming GPUs to compensate for narrow GDDR buses; AMD reused the IP for AI on CDNA 3, where attention KV reuse and weight reuse fit a large LLC unusually well. NVIDIA bet on bigger HBM bandwidth instead (8 TB/s on B200, scaling with HBM4 on Rubin), and AMD bet on the cache.
Off-chip, the HBM capacity grows aggressively: 32 → 64 → 128 → 192 → 256 → 288 GB across MI100 / MI210 / MI250X / MI300X / MI325X / MI350X, matching or exceeding the contemporary NVIDIA flagship in every generation from 2021 onward. The bet is that inference workloads are increasingly capacity-bound, and that the chip with more memory wins.
Numerics
The format trajectory tracks the precision-halving pattern that everyone in AI silicon shares: FP32 → FP16 → FP8 → FP4, restoring accuracy each step with finer-grained scaling. The AMD-specific axis is openness. CDNA 4's FP4 and FP6 use OCP MX block-scale multiplication: the same numeric format as Blackwell's MXFP4 and TPU v8's MXU, but specified by an open consortium (AMD, NVIDIA, Intel, Meta, Microsoft, Qualcomm, ARM) that AMD helped found, rather than by any single vendor. The format that ships in MI355X is identical to what ships in B200 and TPU v8.
The CDNA 4 inflection deserves its own line: per-CU FP64 throughput halved. MI300X served training, HPC, and inference together; MI355X is an AI chip first. The full-rate FP64-matrix bet that powered Frontier hasn't been killed, but it's no longer carrying the weight.
Chiplets
The packaging is where CDNA stops looking like NVIDIA and starts being something else.
CDNA 1's MI100 was monolithic 7 nm. CDNA 2's MI250X was AMD's first multi-chip GPU: two Aldebaran GCDs side-by-side on a 2.5D EFB organic substrate, joined by 4 in-package Infinity Fabric links at 400 GB/s aggregate, but presented to software as two separate GPUs.
CDNA 3 is the move that changed everything. Eight XCDs (TSMC N5, ~115 mm² each) are stacked in 3D via TSMC SoIC hybrid bonding (sub-micron-pitch TSVs, no microbumps) onto four I/O dies (TSMC N6) below. The IODs carry the Infinity Cache, the HBM3 PHYs, the Infinity Fabric links, and PCIe Gen 5; each IOD hosts two XCDs above and two HBM stacks beside. The four IODs are stitched by Infinity Fabric AP at 4.8 TB/s bisection, so the 153-billion-transistor package looks like one GPU to the kernel: cache and address space unified at the IOD layer. NVIDIA stayed monolithic through H100 and only went to two reticle-limit dies on B200 via 2.5D CoWoS-L. AMD got to 3D stacking a generation earlier, at smaller per-die area: different bets on the same packaging frontier.
The MI300A APU pushed the bet further. Replace 2 of the 8 XCDs with three Zen 4 CCDs, leave HBM and Infinity Cache and the IODs intact, and let CPU and GPU share one physical address space backed by HBM3 with hardware coherence. There is no host-device copy. There is no pinned memory. There is no PCIe in the path. Zen 4 cores and CDNA 3 XCDs read from the same pages. NVIDIA's Grace-Hopper bridges two packages over NVLink-C2C; MI300A is one. El Capitan (11,039 nodes of 4× MI300A) is the deployment that justified it.
On CDNA 4's MI355X, eight XCDs are still 3D-stacked via SoIC onto base dies below, but the XCDs move to TSMC N3P with 32 active CUs apiece (256 total, vs 304 on MI300X; the per-XCD count dropped to free area for bigger Matrix Cores and a 160 KB LDS). The four MI300X IODs collapse to two, each twice as wide on TSMC N6, hosting four XCDs above and four HBM3E stacks beside. Each IOD now carries its own 128 MB slice of the 256 MB Infinity Cache, half the HBM PHYs, its share of the Infinity Fabric links, and PCIe Gen 5. Infinity Fabric AP between the two IODs runs at 5.5 TB/s bisection (~15% above CDNA 3), and the eight stacks shift to 12-Hi HBM3E for 288 GB at 8 TB/s, 50% more capacity than MI300X on the same pin count. The package totals 185 billion transistors and still presents as one GPU to the kernel.
Bets
- Bet 1: HPC then AI. HPC and AI are the same bet until they aren't: ship full-rate FP64 matrix from CDNA 2 through CDNA 3, then bifurcate at CDNA 4 once inference economics decisively favour low precision.
- Bet 2: Memory capacity. Match or beat the contemporary NVIDIA flagship on HBM capacity every generation since 2021, and add a 256 MB last-level Infinity Cache that absorbs the reuse H100 must hit HBM for.
- Bet 3: Early 3D-stacking. 3D-stack compute on cache and I/O before NVIDIA does: TSMC SoIC hybrid-bonded XCDs on IODs in 2023, while NVIDIA stayed monolithic until 2025.
- Bet 4: Coherent CPU+GPU. The MI300A APU is the most chiplet-aggressive product ever shipped, and the El Capitan deployment is the proof.
- Bet 5: Open scale-up fabric. UALink and OCP MX over NVLink and proprietary FP4.
Scaling
The memory bet has a scaling consequence: when 8 MI300X chips hold 1.5 TB of HBM and 8 MI350X chips hold 2.3 TB, you can fit a 405B-parameter model in FP8 inside a single 8-GPU box (weights, KV cache, and headroom for longer contexts and bigger batches), where the same model on 8× H100 (640 GB) requires careful sharding. For inference workloads through 2024–2025, AMD's scale-up didn't need to match NVL72 at the rack to be competitive at the box. For training at the frontier, it did, and AMD didn't have an answer until 2026.
Scale-up
Through MI355X, AMD's scale-up means an 8-GPU OAM platform over Infinity Fabric. Each MI300X has 7 IF links (one to every peer in the box) at 128 GB/s bidirectional, giving 896 GB/s of per-GPU mesh bandwidth in a fully-connected all-to-all topology. MI350X bumps each link to 153.6 GB/s (~1,075 GB/s per GPU) but keeps the 8-GPU shape. The platform conforms to OCP's UBB 2.0: the same mechanical socket as an NVIDIA HGX baseboard, so server vendors can ship AMD or NVIDIA on the same chassis without redesigning the system.
What AMD didn't ship through MI355X was a rack-scale equivalent of NVL72. Customers running larger models on MI300X clusters scaled across multiple 8-GPU boxes via Ethernet, paying scale-out latency for what NVIDIA users could keep inside scale-up. This was the gap that mattered for training, and the gap that Helios is built to close.

Helios is AMD's first rack-scale scale-up domain, shipping in 2H 2026 alongside MI455X. 72 GPUs per rack, ~31 TB HBM4, 1.4 PB/s aggregate HBM bandwidth, 2.9 ExaFLOPS FP4 / 1.4 ExaFLOPS FP8, 260 TB/s of scale-up bandwidth, 43 TB/s of scale-out. The form factor is Open Rack Wide (ORW) (Meta's 2025 OCP submission, double-wide and liquid-cooled), not an AMD-proprietary chassis. Building on Meta's reference design rather than designing a rack from scratch is a deliberate AMD bet: any hyperscaler standardised on ORW can deploy Helios without bespoke datacenter facilities work.
The fabric is UALink: Ultra Accelerator Link, an open consortium standard AMD helped found alongside Apple, AWS, Cisco, Google, HPE, Intel, Meta, Microsoft, and Synopsys. UALink 200G 1.0 (April 2025) defines a 200 GT/s lane and 800 Gbps per direction, with switched topologies scaling to 1,024 accelerators per pod. The promise is a cache-coherent interconnect comparable to NVLink but unowned: any vendor can build a UALink switch, any accelerator can talk UALink, the standard belongs to the consortium rather than to the strongest seller.
The catch: native UALink switching silicon won't ship in volume until 2027. Astera Labs' Scorpio, plus competing parts from Auradine, Enfabrica, and Xconn, are all targeting late-2026 / 2027 deployment. Helios at launch uses UALoE (Infinity Fabric tunnelled over standard Ethernet) as a stopgap, preserving the programming model while waiting for native UALink fabric. Native UALink switching arrives with MI500 in 2027. At launch, Helios is closer to a fast Ethernet-tunnelled coherent cluster than to NVL72's true cache-coherent NVLink domain: a real concession on the timeline, paid in exchange for hitting 2H 2026 with a competitive product.
Scale-out
AMD does not ship InfiniBand. The whole scale-out stack is Ethernet, anchored on a different open standard: the Ultra Ethernet Consortium (UEC).
UEC 1.0 (released June 2025) defines Ultra Ethernet Transport (UET): a new RDMA transport over standard Ethernet, with packet spraying, SACK-based selective retransmit, and modern congestion control. UET is not RoCEv2 (which encapsulates InfiniBand transport in Ethernet frames); it's a clean redesign of RDMA semantics for scale-out AI fabrics. AMD is a founding member alongside Broadcom, Cisco, Meta, and Microsoft. Same play as UALink: own the standard, not the implementation.
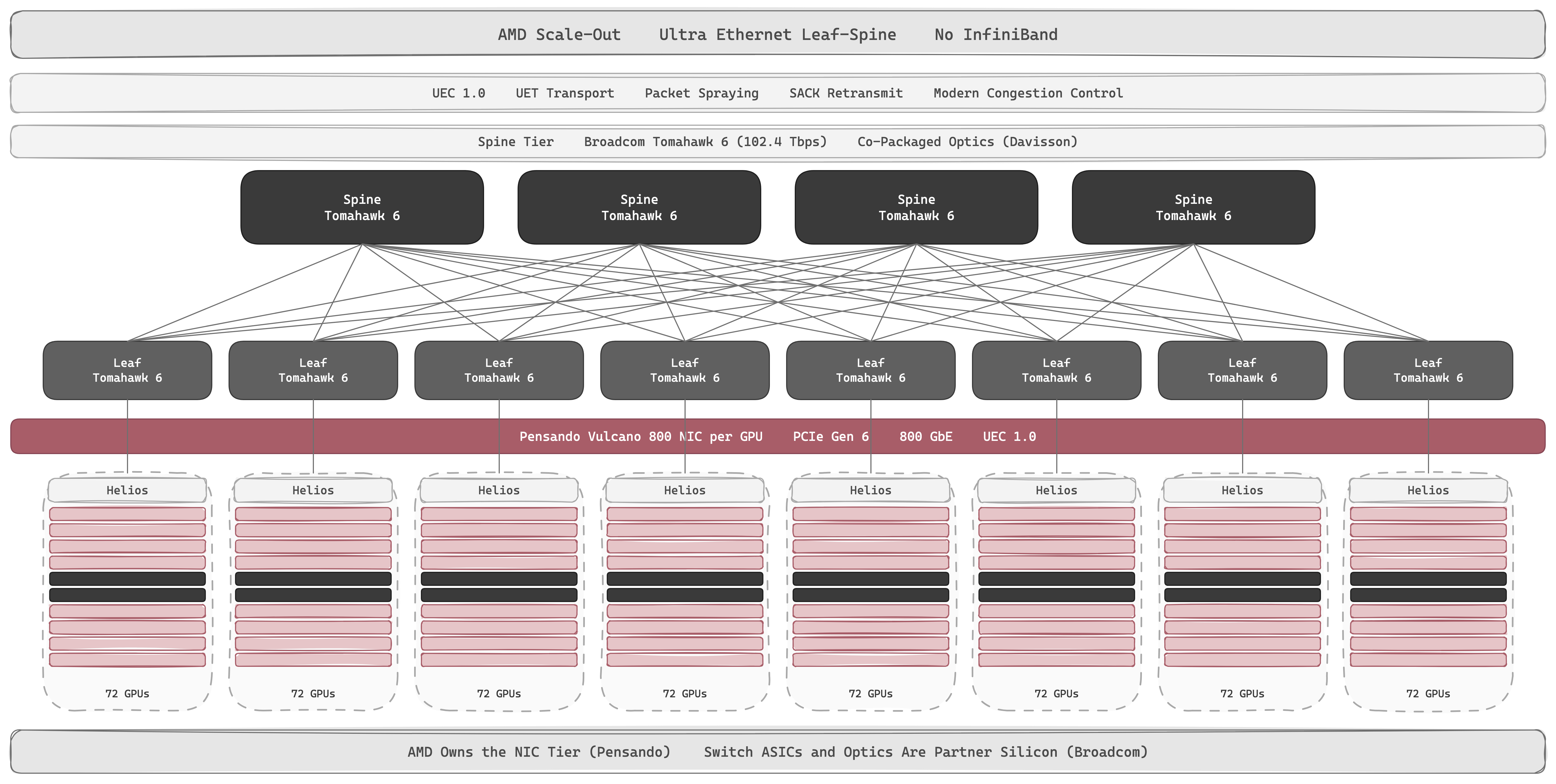
The NIC is Pensando, the networking startup AMD acquired in 2022. Pollara 400 is the current AI NIC: 400 GbE, P4-programmable, UEC-ready, PCIe Gen 5, paired with MI300X / MI355X. Vulcano 800 ships in 2026 alongside MI455X: UEC 1.0 compliant, PCIe Gen 6, native UALink interfaces, 8× the per-GPU scale-out bandwidth of Pollara. Salina 400 is the front-end DPU (16× Arm Neoverse-N1, dual 400 GbE) for storage / SDN / firewall, equivalent to NVIDIA's BlueField, distinct from the AI back-end NIC.
The switch silicon, though, isn't AMD's. Helios's 43 TB/s scale-out fabric runs through Broadcom Tomahawk 6: a 102.4 Tbps Ethernet switch ASIC with co-packaged optics ("Davisson"). AMD has no in-house CPO and no in-house switch ASIC; the optical layer is partner silicon. NVIDIA owns its entire stack: InfiniBand, Spectrum-X Ethernet, ConnectX, BlueField, Quantum-X Photonics CPO, all in-house. AMD owns one tier (NIC + DPU via Pensando) and bets that open standards plus best-of-breed partner silicon will outpace vertical integration.
The industry has moved AMD's way. Dell'Oro reports Ethernet handled more than twice the AI scale-out fabric volume of InfiniBand in 2025; AWS, Microsoft, Meta, Oracle, and xAI have all standardised on Ethernet for their AMD-based AI clusters. The remaining question isn't whether Ethernet can match InfiniBand on RDMA semantics (UEC closes that gap) but whether Helios can close the rack-scale gap with NVL72 fast enough to win frontier training workloads that today default to NVIDIA.
Software
ROCm is the open-source counterpoint to CUDA. Where NVIDIA's stack is proprietary and vertically integrated (cuBLAS, cuDNN, TensorRT-LLM ship as binary blobs maintained by NVIDIA alone), ROCm is GitHub-native and bets on open standards (PyTorch, Triton, vLLM, OCP MX) rather than a walled-garden library set. The software gap with NVIDIA is real, but AMD's strategy is to close it through the open community rather than build a parallel CUDA stack from scratch.
The bottom of the stack is HIP, AMD's CUDA-compatible C++ runtime. hipify translates CUDA source to HIP automatically. Bulk HPC code (HACC, Laghos, QMCPack) ports at 80–95% out of the box: the CORAL-2 number. Modern AI kernels port worse: anything that reaches for Hopper- or Blackwell-specific primitives (TMA descriptors, wgmma, tcgen05.mma) has no clean ROCm analog and has to be rewritten by hand.
Above HIP sits a library tier structured to mirror NVIDIA's, one-to-one by name: rocBLAS for cuBLAS; hipBLASLt for cuBLASLt; MIOpen for cuDNN; RCCL for NCCL; Composable Kernel (and its modern ck-tile DSL) for CUTLASS; rocprofv3 / rocprof-sys / rocprof-compute for the Nsight family. There is no first-party analog of TensorRT-LLM, though. AMD's answer is to back vLLM as the open-source serving engine and ship AMD-specific operators (AITER) that plug into it; the dedicated ROCm CI for vLLM took test-pass rate from 37% to 93% across early 2026.
The PyTorch path is first-class. Eager-mode PyTorch has run on ROCm since 2018; torch.compile lowers through Triton, and Triton's ROCm backend (with AOTriton for ahead-of-time math kernels) is upstream. There is no XLA-style intermediate IR; ROCm compiles direct to HIP / Triton / CK. As Triton becomes the default kernel path in PyTorch, much of the porting cost evaporates: a kernel that runs through torch.compile works on both CUDA and ROCm without source change. This is the architectural bet beneath AMD's open strategy: Triton's Python DSL becomes the cross-vendor lingua franca that sidesteps the need for a CUDA-equivalent kernel ecosystem.
FlashAttention is the load-bearing case. FA2 is production on MI300X via Composable Kernel; PyTorch defaults to CK or AOTriton on ROCm. FA3 (Hopper-tuned) is partially supported via AITER + CK, but Dao-AILab's canonical implementation remains CUDA-only. FA4 (Blackwell, March 2026) has no ROCm port at all. HipKittens, Hazy Research's MI355X port of ThunderKittens (November 2025), claims forward-pass parity with hand-tuned AITER in ~500 lines. The pattern: open-source academic kernels close the AMD tail months after NVIDIA's, not years.
Production deployment has validated the strategy. Microsoft Azure's ND MI300X v5 instances went GA in May 2024; OpenAI runs GPT inference on them. Meta ships Llama 3 / Llama 4 inference on MI300X via the Grand Teton platform. Oracle OCI's BM.GPU.MI300X.8 went GA in September 2024, with MI355X following in 2026. These are real serving fleets at hyperscaler scale, not pilots.
The honest gap is still real. Independent benchmarks (Phoronix, March 2026) put ROCm 7.2 at 10–25% slower than equivalent CUDA on standard PyTorch / vLLM / SGLang workloads, at equivalent precision on equivalent silicon. ROCm 7 reached feature parity but not perf parity. The FlashAttention-4 tail (research code that exploits Blackwell's newest primitives) is where NVIDIA's moat remains most durable; it has no clean ROCm analog and waits for a hand-written AITER kernel or HipKittens-class community port. NVIDIA ships engineers inside frontier labs; AMD ships kernels through GitHub. The strategies converge on common workloads (Llama inference, attention, dense transformer training) but the long tail of novel research code still costs MI300X / MI355X deployments engineering time NVIDIA users don't pay.
Comparison
Per-chip
| Company | Year | Chip | HBM | HBM BW | Flagship dense FLOPs | TDP | Scale-up BW |
|---|---|---|---|---|---|---|---|
 | 2023 | H100 SXM5 | 80 GB HBM3 | 3.4 TB/s | 1.98 PetaFLOPS FP8 | 700 W | 900 GB/s |
| 2024 | H200 SXM | 141 GB HBM3e | 4.8 TB/s | 1.98 PetaFLOPS FP8 | 700 W | 900 GB/s | |
| 2024 | B200 | 192 GB HBM3e | 8 TB/s | 4.5 PetaFLOPS FP8 / 9 PetaFLOPS FP4 | 1,000 W | 1.8 TB/s | |
| 2025 | B300 | 288 GB HBM3e | 8 TB/s | 7.5 PetaFLOPS FP8 / 15 PetaFLOPS FP4 | 1,400 W | 1.8 TB/s | |
| 2026 | Rubin | 288 GB HBM4* | ~13 TB/s* | ~17 PetaFLOPS FP8* / ~50 PetaFLOPS FP4* | ~1,500 W* | 3.6 TB/s | |
| 2027 | Rubin Ultra | 1 TB HBM4e* | ~32 TB/s* | ~33 PetaFLOPS FP8* / ~100 PetaFLOPS FP4* | ~1,800 W* | 3.6 TB/s | |
 | 2023 | TPU v5p | 95 GB HBM2e | 2.8 TB/s | 0.46 PetaFLOPS BF16 | n/d | 1.2 TB/s |
| 2025 | TPU Ironwood (v7) | 192 GB HBM3e | 7.4 TB/s | 4.6 PetaFLOPS FP8 | n/d | 1.2 TB/s | |
| 2026 | TPU v8t Sunfish | 216 GB HBM3e | 6.5 TB/s | 12.6 PetaFLOPS FP4 | n/d | n/d | |
 | 2023 | MI300X | 192 GB HBM3 | 5.3 TB/s | 2.6 PetaFLOPS FP8 | 750 W | 896 GB/s |
| 2024 | MI325X | 256 GB HBM3e | 6.0 TB/s | 2.6 PetaFLOPS FP8 | 1,000 W | 896 GB/s | |
| 2025 | MI355X | 288 GB HBM3e | 8 TB/s | 10 PetaFLOPS FP8 / 20 PetaFLOPS FP4 | 1,400 W | 1,075 GB/s | |
| 2026 | MI455X | TBD | TBD | ~40 PetaFLOPS FP4* | TBD | n/d |
Per-rack / pod
| Company | Year | System | Chips | Aggregate dense FLOPs | HBM total | Scale-up bisection | Per-chip NIC | Power | Cooling |
|---|---|---|---|---|---|---|---|---|---|
| 2023 | HGX H100 | 8 | 16 PetaFLOPS FP8 | 640 GB | 7.2 TB/s | 400 Gbps (CX-7) | ~10 kW | Air |
| 2024 | HGX H200 | 8 | 16 PetaFLOPS FP8 | 1.1 TB | 7.2 TB/s | 400 Gbps | ~10 kW | Air | |
| 2024 | GB200 NVL72 | 72 | 360 PetaFLOPS FP8 / 720 PetaFLOPS FP4 | 13.4 TB | 130 TB/s | 800 Gbps (CX-8) | ~120 kW | Liquid | |
| 2025 | GB300 NVL72 | 72 | 540 PetaFLOPS FP8 / 1,100 PetaFLOPS FP4 | 20.7 TB | 130 TB/s | 800 Gbps | ~120 kW | Liquid | |
| 2026 | NVL144 | 144 | ~1.2 ExaFLOPS FP8 / ~3.6 ExaFLOPS FP4 | ~21 TB | ~260 TB/s* | 1.6 Tbps (CX-9) | ~200 kW* | Liquid | |
| 2027 | NVL576 (Kyber) | 576 | ~5 ExaFLOPS FP8 / ~15 ExaFLOPS FP4 | ~144 TB | n/d | 1.6 Tbps | ~600 kW* | Liquid | |
| 2023 | TPU v5p pod | 8,960 | 4.1 ExaFLOPS BF16 | 852 TB | (3D torus) | (ICI = scale-up + scale-out) | n/d | Liquid |
| 2025 | TPU Ironwood pod | 9,216 | 42.5 ExaFLOPS FP8 | 1.77 PB | (3D torus) | optical OCS | ~10 MW* | Liquid | |
| 2026 | TPU v8t Sunfish pod | 9,600 | 121 ExaFLOPS FP4 | ~2 PB | (Boardfly) | optical OCS | n/d | Liquid | |
| 2023 | MI300X 8-GPU OAM | 8 | 21 PetaFLOPS FP8 | 1.5 TB | 7.2 TB/s | 400 Gbps | ~10 kW | Air |
| 2024 | MI325X 8-GPU OAM | 8 | 21 PetaFLOPS FP8 | 2.0 TB | 7.2 TB/s | 400 Gbps | ~12 kW* | Air | |
| 2025 | MI355X 8-GPU OAM | 8 | 80 PetaFLOPS FP8 / 160 PetaFLOPS FP4 | 2.3 TB | 8.6 TB/s | 400 Gbps | ~16 kW* | Liquid | |
| 2026 | Helios (MI455X) | 72 | 1.4 ExaFLOPS FP8 / 2.9 ExaFLOPS FP4 | 31 TB | 260 TB/s | n/d | n/d | Liquid |
What this shows
- Per-chip FP8 has converged. B200 (4.5 PF), Ironwood (4.6 PF), and MI355X (10 PF) sit within ~2× of each other. The per-chip arms race is close; the rack and pod are where the architectures diverge.
- HBM capacity is AMD's persistent win. 192 → 256 → 288 GB across 2023–2025 has matched or beaten NVIDIA every generation. NVIDIA caught up at 288 GB only with B300 (late 2025); Rubin Ultra retakes the lead at 1 TB / package in 2026.
- Rack-scale scale-up is NVIDIA's win until 2026. GB200 / GB300 NVL72 was the only coherent rack-scale domain shipping in 2024–2025; AMD scaled up at the box and didn't reach rack scale until Helios. The TPU sidesteps the question: its torus is the rack and the cluster at once.
- TPU pods dwarf any NVIDIA rack in chip count. Ironwood pod = 9,216 chips for 42.5 ExaFLOPS FP8; NVL576 = 576 GPUs for ~5 ExaFLOPS FP8. The TPU's flat-rate-per-chip × massive-pod recipe yields more aggregate compute per system, at the cost of per-chip bandwidth.
- Power per chip is rising fast. 700 W (Hopper) → 1,000 W (Blackwell, MI325X) → 1,400 W (B300, MI355X) → ~1,800 W (Rubin Ultra, analyst). Liquid cooling becomes mandatory above ~1,000 W; air cooling effectively ends with Hopper.
- Scale-out NIC bandwidth doubles each NVIDIA generation. 400 Gbps (CX-7, Hopper) → 800 Gbps (CX-8, Blackwell) → 1.6 Tbps (CX-9, Rubin). AMD lags one generation (Pollara 400 → Vulcano 800), reflecting Pensando's smaller install base and later integration.